Machine Learning, a prominent topic in Artificial Intelligence domain, has been in the spotlight for quite some time now. This area may offer an attractive opportunity, and starting a career in it is not as difficult as it may seem at first glance. Even if you have zero-experience in math or programming, it is not a problem. The most important element of your success is purely your own interest and motivation to learn all those things.
Machine learning is an in-demand skill to add to your resume. We walk through steps for wading into machine learning with the help of Python.
Have you wondered what it takes to get started with machine learning? In this article, I will walk through steps for getting started with machine learning using Python. Python is a popular open source programming language and it is one of the most-used languages in artificial intelligence and other related scientific fields. Machine learning (ML), on the other hand, is the field of artificial intelligence that uses algorithms to learn from data and make predictions. Machine learning helps predict the world around us.From self-driving cars to stock market predictions to online learning, machine learning is used in almost every field that utilizes prediction as a way to improve itself. Due to its practical usage, it is one of the most in-demand skills right now in the job market. Also, getting started with Python and machine learning is easy as there are plenty of online resources and lots of Python machine learning libraries available.
Brush up your Python skills
Because Python is extremely popular, both in the industrial and scientific communities, you will have no difficulty finding Python learning resources. If you are a complete beginner, you can start learning Python using online materials, such as courses, books, and videos. For example:
Step 1. Brush up Your Math Skills Needed for Python Mathematical Libraries
A person working in the field of AI and ML who doesn’t know math is like a politician who doesn’t know how to persuade. Both have an inescapable area to work upon!
So yes, you can’t deal with ML and Data Science projects without leastwise minor math knowledge basis. However, you don’t need to have a degree in Mathematics to succeed. In my personal experience, devoting at-least 30–45 minutes every day will bear much fruit and you’ll understand and learn advanced Python topics for Maths and Statistics faster.
You need to read or refresh the underlying theory. No need to read a whole tutorial, just focus on key concepts.
Here are 3 steps to learn the mathematics needed for analysis and machine learning:
1 — Linear algebra for data analysis: Scalars, Vectors, Matrices, and Tensors
For example, for the Principal Component Method, you need to know the eigenvectors, and the regression requires matrix multiplication. In addition, machine learning often works with high-dimensional data (data with many variables). This data type is best represented by matrices.
2 — Mathematical Analysis: Derivatives and Gradients
Mathematical analysis underlies many machine learning algorithms. Derivatives and gradients will be needed for optimization problems. For example, one of the most common optimization methods is gradient descent.
For quick learning of Linear Algebra and Math Analysis, I would like to recommend these courses:
Khan Academy provides short practical lessons on linear algebra and math analysis. They cover the most important topics.
MIT OpenCourseWare offers great courses for learning math for ML. All video lectures and study materials are included.Neural Networks are becoming more and more popular every day and as a core field of Machine Learning and Artificial Intelligence they are going to play a major role in the technology, science and industry over the next years. This high popularity has given rise to many frameworks that allow you to implement Neural Networks very easily without knowing the complete theory behind them. On the other side, the strict theoretical proof of the Neural Networks algorithm demands a very high level of mathematics.
In this post we will do something between. Specifically, in order to get a more solid understanding of the Neural Networks we will go through the actual implementation of a NN from scratch without using any framework. This may be a bit more difficult than using a framework but you will gain a much better understanding of the mechanism behind Neural Networks. Of course in large scale projects a framework implementation is preferred as it is easier and faster to set up. Also we will not give mathematical proofs of why the code below works as we suppose a basic understanding of the theory behind them.
The tools used in this tutorial are just Python with numpy library(Scientific library for Linear Algebra operations). Supposing that you have python and pip installed, you can install numpy by running this command:
pip install numpy
A Neural Network is actually a function of many variables: It takes an input, makes computations and produces an output. We like to visualise it as neurons in different layers, with each neuron in a layer connected with all neurons in the previous and the next layer. All the computations take place inside those neurons and depend on the weights that connect the neurons with each other. So all we have to do is learn the right weights in order to get the desired output.
Their structure is generally very complex including a lot of layers and even more than a million neurons in order to be able to handle the large datasets of our era. However, in order to understand how large deep neural networks work one should start with the simplest ones.
Consequently, below we will implement a very simple network with 2 layers. In order to do that we need a very simple dataset as well, so we will use the XOR dataset in our example, as shown below. A and B are the 2 inputs of the NN and A XOR B is the output. We will try to make our NN learn weights such that whatever pair of A and B it takes as input, it will return the corresponding result.


So, let’s start!
First we need to define the structure of our Neural Network. Because our dataset is relatively simple, a network with just a hidden layer will do fine. So we will have an input layer, a hidden layer and an output layer. Next we need an activation function. The sigmoid function is a good choice for the last layer because it outputs values between 0 and 1 while tanh(hyperbolic tangent) works better in the hidden layer, but every other commonly used function will work(e.g. ReLU). So the structure of our Neural Network will look like this:
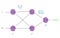

Here, the parameters to be learned are the weights W1, W2 and the biases b1, b2. As you can see W1 and b1 are the connect the input layer with the hidden layer while W2, b2 connect the hidden layer with the output layer. From the basic theory of NNs we know that the activations A1 and A2 are calculated as following:
A1 = h(W1*X + b1)
A2 = g(W2*A1 + b2)
where g and h are the two activation functions we chose(for us sigmoid and tanh) and W1, W1, b1, b2 are generally Matrices.
Now let’s jump into the actual code. The code style follows the guidelines proposed by prof. Andrew Ng at this course in general.
Note: You can find the fully working code in my repository here
First we will implement our sigmoid activation function defined as follows: g(z) = 1/(1+e^(-z)) where z will be a matrix in general. Luckily numpy supports calculations with matrices so the code is relatively simple:
Next we have to initialize our parameters. Weight matrices W1 and W2 will be randomly initialized from a normal distribution while biases b1 and b2 will be initialized to zero.The function initialize_parameters(n_x, n_h, n_y) takes as input the number of units in each of the 3 layers and initializes the parameters properly:
The next step is to implement the Forward Propagation. The function forward_prop(X, parameters) takes as input the neural network input matrix X and the parameters dictionary and returns the output of the NN A2 with a cache dictionary that will be used later in back propagation.
We now have to compute the loss function. We will use the Cross Entropy Loss function. Calculate_cost(A2, Y) takes as input the result of the NN A2 and the groundtruth matrix Y and returns the cross entropy cost:
Now the most difficult part of the Neural Network algorithm, Back Propagation. The code here may seem a bit weird and difficult to understand but we will not dive into details of why it works here. This function will return the gradients of the Loss function with respect to the 4 parameters of our network(W1, W2, b1, b2):
Nice, now we have the all the gradients of the Loss function, so we can procceed to the actual learning! We will use Gradient Descent algorithm to update our parameters and make our model learn with the learning rate passed as a parameter:
By now we have implemented all the functions needed for one circle of training. Now all we have to do is just put them all together inside a function called model() and call model() from the main program.
Model() function takes as input the features matrix X, the labels matrix Y, the number of units n_x, n_h, n_y, the number of iterations we want our Gradient Descent algorithm to run and the learning rate of Gradient Descent and combines all the functions above to return the trained parameters of our model:
The training part is now over. The function above will return the trained parameters of our NN. Now we just have to make our prediction. The function predict(X, parameters) takes as input the matrix X with elements the 2 numbers for which we want to compute the XOR function and the trained parameters of the model and returns the desired result y_predict by using a threshold of 0.5:
We are done with all the functions needed finally. Now let’s go to the main program and declare our matrices X, Y and the hyperparameters n_x, n_h, n_y, num_of_iters, learning_rate:
Having all the above set up, training the model on them is as easy as calling this line of code:
Finally let’s make our prediction for a random pair of numbers, let’s say (1,1):
That was the actual code! Let’s see our results. If we run our file, let’s say xor_nn.py, with this command
python xor_nn.py
we get the following result, that is indeed correct becase 1XOR1=0!
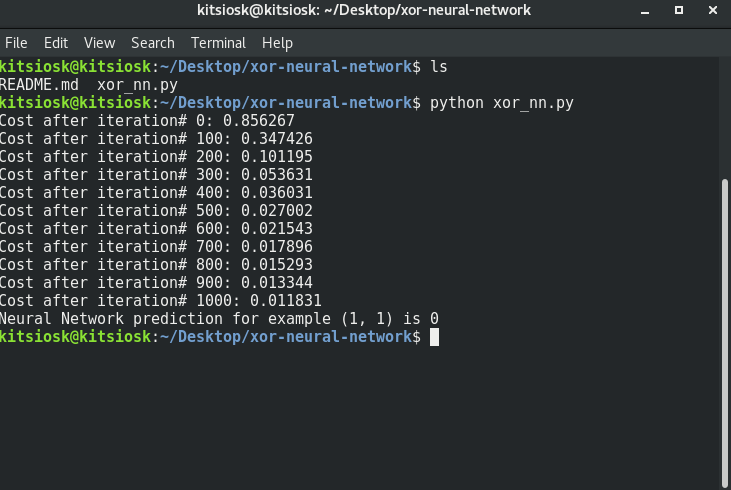
That’s it! We have trained a Neural Network from scratch using just Python.
Of course in order to train larger networks with many layers and hidden
units you may need to use some variations of the algorithms above, for example you may need to use Batch Gradient Descent instead of Gradient Descent or use many more layers but the main idea of a simple NN is as described above.
Feel free to play with the hyperparameters yourself and try different architectures of the Neural Network. For example you can try a smaller number of iterations because the Cost seems to be going down quickly and 1000 of them may be a bit large. Remember that you can find the fully working code in my gitlab repository
Thanks for reading


0 comments: